Positional Encoding
Sinusoidal
Then add it to the input vectors.
NoPE
Length Generalization of Causal Transformers without Position Encoding
No positional encoding.
Additive
ALiBi
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
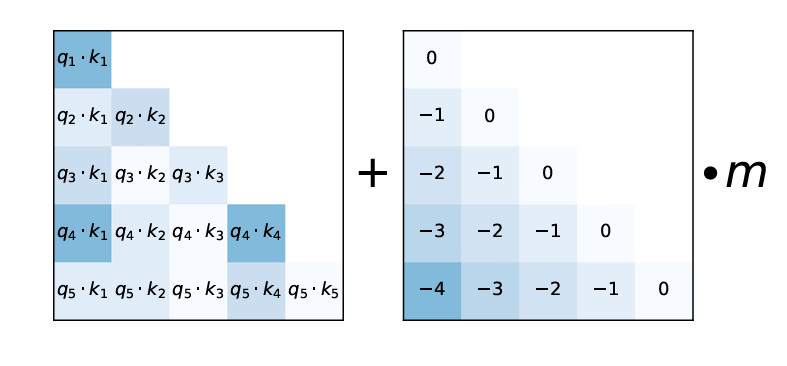
- Original attention score:
- With AliBi:
is a const head-specific scalar: for the th head. - No positional encoding.
T5's RPE
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
is hyper-parameter. are learnable scalars.
Kerpel
KERPLE: Kernelized Relative Positional Embedding for Length Extrapolation
Sandwich
Dissecting Transformer Length Extrapolation via the Lens of Receptive Field Analysis
FIRE
Functional Interpolation for Relative Positions Improves Long Context Transformers
is MLP. is monotonically increasing (e.g. ). is a learnable scalar.
CaPE
CAPE: Context-Adaptive Positional Encoding for Length Extrapolation
is a two-layer LeakyReLU neural network. is positional bias matrices (e.g. ALiBi and FIRE).
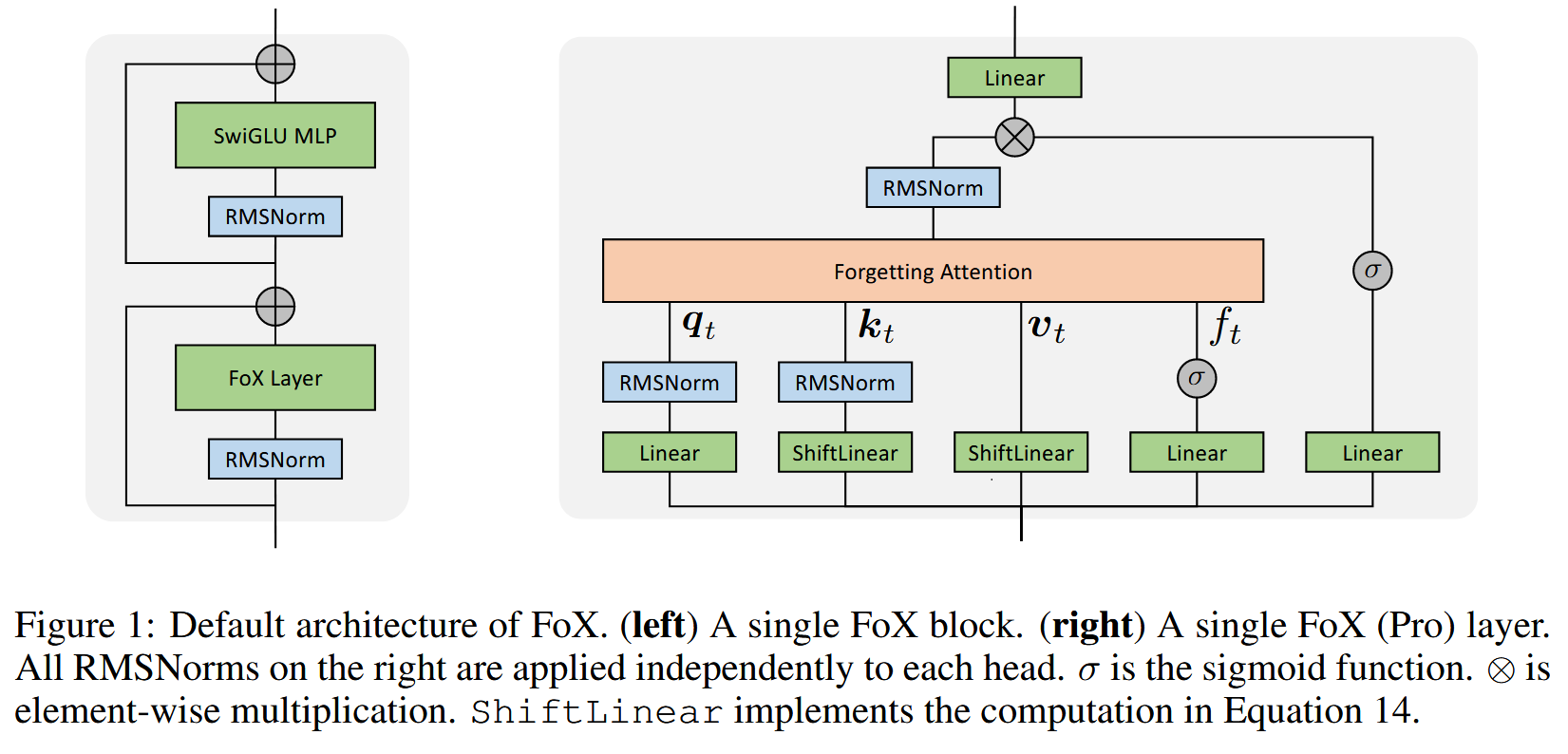
FoX
Forgetting Transformer: Softmax Attention with a Forget Gate
- Dynamic down-weighting of past information.
- No need of position embeddings.
- Compatible with FlashAttention.
Scalar Forget Gate
Where
and are learnable and per-head (for multiple head attention). Cumulative Forget Factor
FoX (Pro)
CoPE
Contextual Position Encoding: Learning to Count What's Important
- Dynamically decide which tokens should be counted based on the context.
- More flexible position addressing (e.g. i-th specific word, noun, or sentence).
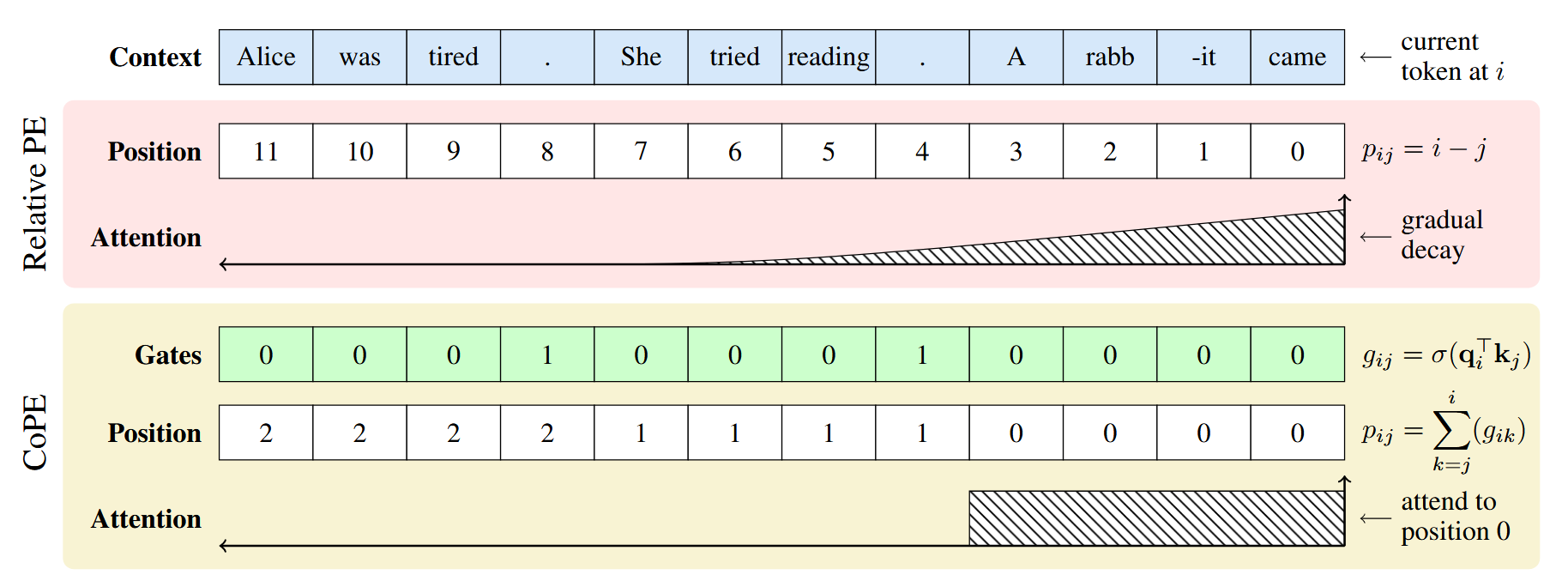
Gate Computation
Contextual Position Calculation
Position Embedding Interpolation
- Because
may be a fraction, interpolation is used to compute the embedding vector. - For each integer position, a learnable embedding vector
is used. - For decimal position:
- Because
Attention Calculation
Raw:
Optimized: (Interacts with the query vector before interpolation)
- Pre-computed for all integer positions:
- Interpolating scalar attention contribution:
SBA
Scaling Stick-Breaking Attention: An Efficient Implementation and In-depth Study
- Using the stick-breaking process as a replacement for softmax for attention.
- Naturally incorporating recency bias.
- No need of positional encoding.
Original Logits
Breakpoint Possibility
Attention Weights
- From
to (backwards in time).
- From
Output
Numerically Stable Implementation
By Log-Space Formulation.
Sigmoid in log-space:
Where
is commonly known as softplus(x). Compute
in log-space: Stabilized softplus:
Rotary
RoPE
Roformer: Enhanced transformer with rotary position embedding
where
It works because
2D-RoPE
LieRE
For high dimension (
). Learn skew-symmetric basis of matrices
Skew-symmetric:
For position
, encode as ,
ComRoPE
is a Relative Positional Encoding if and only if there is a satisfies: where
is a similarity function In this form, RoPE can be represented as:
which also satisfies:
is a rotation matrix function if THEOREM:
Let
Then we need to find
that satisfies above. ComRoPE-AngleMatrices:
where
is trainable ComRoPE-LinearlyDependent:
Specially,
| Method | Commutativity | Extra Parameters | Extra Time Complexity |
|---|---|---|---|
| APE | — | ||
| Vanilla RoPE | Yes | 0 | |
| LieRE | Commonly Not | ||
| ComRoPE-AP | Yes | ||
| ComRoPE-LD | Yes |
FoPE
Fourier Position Embedding: Enhancing Attention's Periodic Extension for Length Generalization
TaPE
conTextualized equivariAnt Position Embedding
Rethinking Addressing in Language Models via Contexualized Equivariant Positional Encoding
- Permutation Equivariance