Linear Attention
Original Linear Attention
The original attention mechanism is defined as:
Complexity:
If we omit the softmax operator it becomes:
Complexity:
which is of linear complexity.
In Autoagressive Models
In autoregressive models like GPT we need a causal mask:
Removing softmax yields:
Unfortunately the Hadamard product (
RNN-like Sequential Form
Even though, Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention observes that the inference equation can be written in an RNN-like form:
This achieves linear time, but introduces two drawbacks:
Memory during autograd:
High memory footprint during autograd: every intermediate state
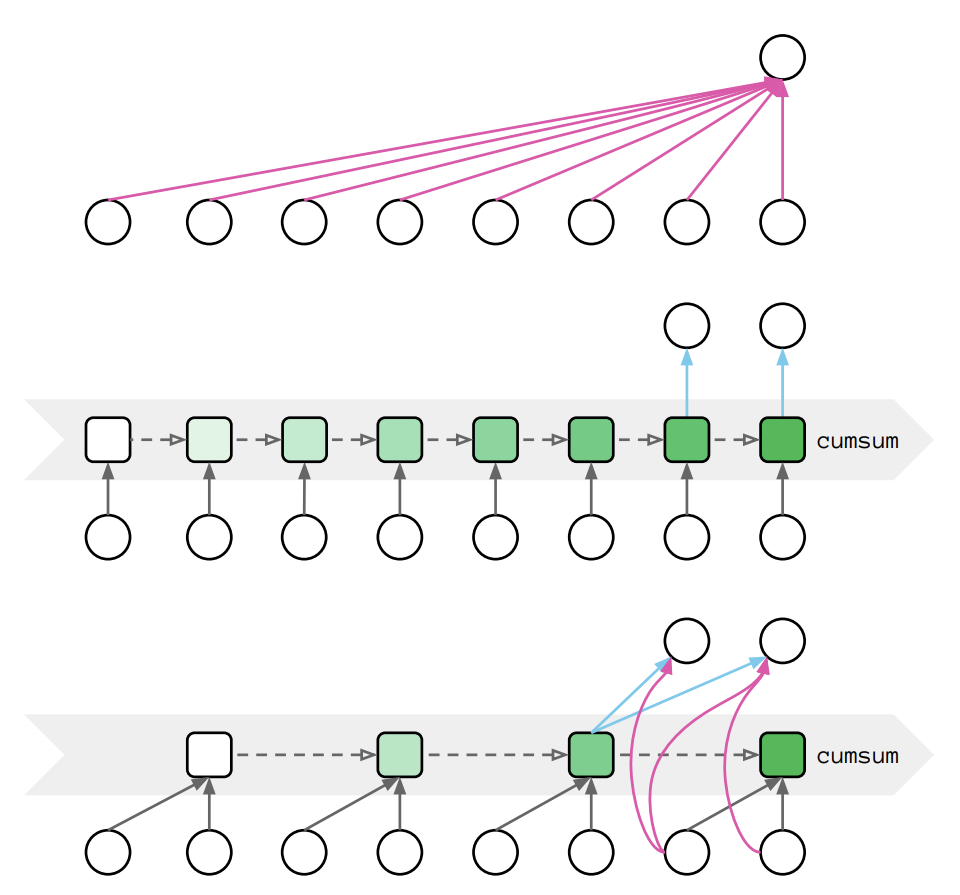
must be stored, resulting in memory usage. The authors alleviate this by recomputing on-the-fly during back-propagation. Parallelism:
Poor training parallelism: the update is element-wise instead of large matrix multiplications, which under-utilizes GPU tensor cores.
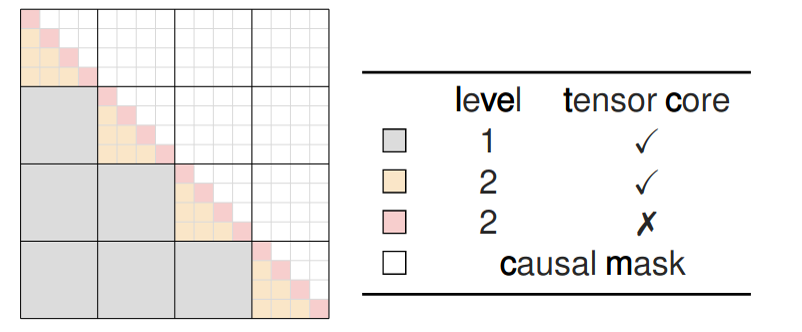
A compromise is the chunkwise algorithm proposed in Transformer Quality in Linear Time, which allows parallelism while remaining linear.
From up to bottom: Parallel form, recurrent form, chunkwise parallel form:
Gated Linear Attention
A learnable 2D forget gate
This is very general and encompasses many recent RNNs with 2D hidden states:

Gated Linear Attention Transformers with Hardware-Efficient Training also proposed its GLA:
- Recurrent form:
- Parallel form:
Chunkwise parallel:
References
Sonta. "Zhihu answer." https://www.zhihu.com/question/9740764576/answer/80735153803
Katharopoulos A., Vyas A., Pappas N., Fleuret F. "Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention." https://arxiv.org/abs/2006.16236
Vyas A., Katharopoulos A., Fleuret F. "Transformer Quality in Linear Time." https://arxiv.org/abs/2202.10447
Yang S.L., Wang B.L., et al. "Gated Linear Attention Transformers with Hardware-Efficient Training." https://arxiv.org/abs/2312.06635